
Sesja jest powiernikiem Twoich danych w określonym oknie pracy. Pozwala na szybki dostęp do informacji i jest zapominalska. Dane, trzymane w sesji są o tyle bezpieczne o ile bezpieczny jest Twój serwer – to właśnie po stronie serwera trzymane są wszystkie dane w kontekście sesji.
Nie istniejesz dla mnie, nie ma cię w mojej pamięci, choć tyle razy robiłeś wszystko, by się w niej znaleźć… Nie istniejesz dla mnie, nie ma cię.
Cześć 

Mechanizm sesji jest podstawą gdy przechodzimy przez typowo uczelniany tryb nauczania – tylko bardzo często na tym etapie brakuje nam szerszego kontekstu jak to jest używane. W rezultacie może to skutkować tym, że zapominamy jak to działa.
W dzisiejszym artykule:
Czym jest sesja?
Protokół HTTP jest bezstanowy, co oznacza, że każde żądanie jakie wysyłasz z przeglądarki do serwera nie wie, że to ciągle jesteś Ty. Jednak jakaś intuicja podpowiada nam, że wszystko to klei się jakoś inaczej – nie muszę za każdym odświeżeniem strony (czy nawet przejściem do nowej zakładki) logować się do serwisu, który odwiedzałem 2 minuty temu.
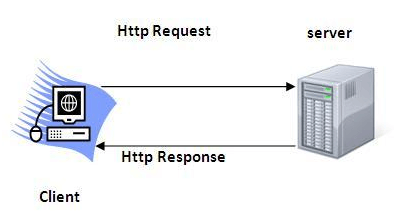
Tu wkracza mechanizm sesji. Pozwala ona na rozwiązanie tego problemu wprowadzając stan, gdzie klient (przeglądarka) oraz serwer HTTP mogą wymieniać wiele żądań i wiedzieć że ty to ty używając unikalnego identyfikatora, który mówi serwerowi – oo, ciebie kojarzę, 5 minut temu przeglądałeś produkty kuchenne.
Javowa implementacja mechanizmu sesji opisuje to tak (źródło):
Provides a way to identify a user across more than one page request or visit to a Web site and to store information about that user. |
Do czego służy sesja?
Wiemy już, że sesja wprowadza stan pozwalający na zapamiętanie użytkownika pomiędzy wieloma żądaniami. Pytanie – po co?
Przykład: kupujesz coś na allegro, wybierasz jedną rzecz a później przechodzisz do koszyka z wybranym produktem – czysto teoretycznie, po przejściu do koszyka, gdzie wykonywane jest nowe żądanie, serwer nie wie że to znowu jesteś ty. Jeżeli tak by było to jak ma dostarczyć ci twój koszyk? W końcu ciężko jest sobie wyobrazić przypadek gdy klikamy w koszyk a tam pustka – no bo serwer się obraził i o nas zapomniał.
Dodatkowo weź pod uwagę, że często takie dane ogólno-kontekstowe (np. imię zalogowanego użytkownika), będzie Ci łatwiej przechowywać właśnie w sesji. Jeżeli twoja aplikacja wyświetla na każdej stronie imię zalogowanego użytkownika, to po co masz za każdym razem sięgać po te dane z jakiejś bazy? To spowodowałoby tylko dodoatkowe, niepotrzebne zapytania do bazy i obciążyło całe działanie systemu jeszcze bardziej.
Używając sesji do trzymania danych ogólnych o tym co robi/kim jest użytkownik, pozwoli ci na szybki dostęp do takich danych. Nie oznacza to wcale, że zawsze będziesz unikał bazy danych bo dostęp jest 'drogi’. Dane sesyjne możesz również trzymać w bazie. Np. twoja aplikacja ma relacyjną bazę, gdzie przechowujesz wszystkie informacje o użytkownikach. I faktycznie – baza nie jest najszybsza a zapytania zajmują sporo czasu. Możesz się zdecydować na to, żeby dane w ramach twojej sesji były natomiast trzymane w jakiejś bazie nierelacyjnej, do której dostęp będzie o wiele szybszy – np. Redis. Nie zawsze zapisywanie wszystkiego in-memory jest najlepsze (bo teoretycznie daje najszybszy dostęp) i musisz sam analizować sytuacje jakie się u ciebie pojawiają.
Jak działa mechanizm sesji?
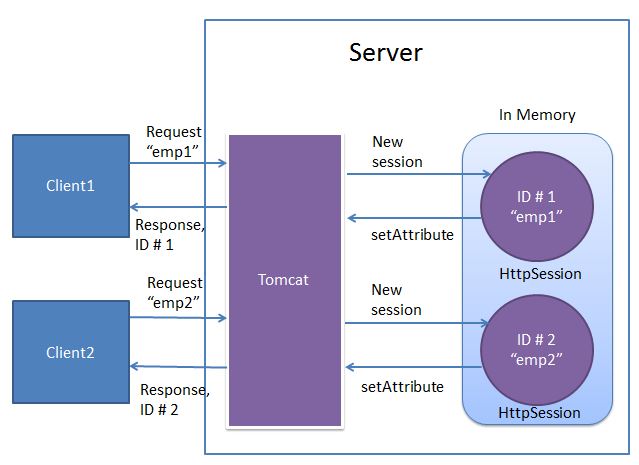
Jak już wcześniej wspominałem sesja składa się z unikalnego identyfikatora, który tworzy jasny kontrakt mówiący że ty to ty. Aby tak się zadziało, klient oraz serwer muszą wiedzieć o istnieniu tego identyfikatora. Identyfikator ten w przypadku servletów będzie się nazywał JSESSIONID (w przypadku php – PHPSESSID).
Wyobraź sobie logowanie do facebooka. Jesteś tam pierwszy raz – niezalogowany. Uwierzytelniasz się – serwer przypisuje ci unikalny identyfikator i go odsyła (lub np. ustawia ciasteczko z tą wartością). Od razu serwer ustawia także czas trwania takiej sesji – co oznacza, że jeżeli wejdziesz na facebooka po kilku godzinach to nie musisz się ponownie logować – sesja nadal trwa. Dlaczego nie musisz się logować ponownie? Twoja przeglądarka w momencie żądania strony wysyła ciasteczko z identyfikatorem do serwera facebooka a ten widzi, że taki identyfikator jest już w jego datastorze. Teraz na podstawie logiki oraz żądania jakie było wysłane, serwer zwraca odpowiedni kontekst (stronę) razem z identyfikatorem sesji.
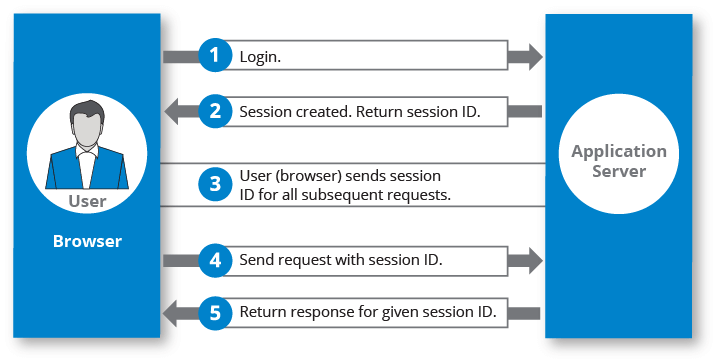
Czyli działanie sesji można podsumować w następujących podpunktach:
- Serwer otwiera sesję (ustawia ciasteczko)
- Serwer ustawia zmienną sesyjną
- Klient zmienia strony (wywołuje żądania)
- Klient, razem z żądaniami wysyła wszystkie ciasteczka do serwera (włącznie z identyfikatorem sesji z kroku pierwszego)
- Serwer odczytuje identyfikator sesji z ciasteczka
- Serwer próbuje znaleźć podany identyfikator sesji
- Serwer znajduje identyfikator, pozwalając na dostęp do danych ze zmiennej sesyjnej
Podsumowanie
Sesja pomimo swojego banalnego przeznaczenia nie jest czymś prostym. W tym artykule omówiłem ogólniki działania sesji w pojęciu aplikacji na jednym serwerze. Co w przpadkach gdy po drodze jest gdzieś load balancer i to on kieruje nas na odpowiedni serwer? Gdzie wtedy będzie trzymany unikalny identyfikator sesji? Kto będzie nim zarządzać?
Obecnie nie jestem w stanie dać Ci odpowiedzi na te pytania w sposób sensowny. Jeżeli masz doświadczenie w zarządzaniu sesją w środowiskach rozproszonych to odezwij się w komentarzu. Z chęcią o tym pogadam i dodam artykuł o tym 🙂
Źródła z dzisiejszego wpisu:
- How does a web session work ?
- Session Management in Java – HttpServlet, Cookies, URL Rewriting
- How Sessions work in Web Servers
Za tydzień
Zrobimy mały krok w bok w stronę Hibernate’a. I zastanowimy się czy aby mapowania działały prawidłowo musimy używać getterów i setterów.
Sesja w środowiskach rozproszonych może być bardzo trudnym zagadnieniem, szczegolnie jezeli masz wiecej niz jeden region. Replikacja danych po między regionami, to ważny aspekt, którego nie można pominać. Dobrze sobie z tym radzi CouchbaseDB.
Z mojego doświadczenia warto tez uważać na serializację sesji w Javie, może się to odbić czkawką oraz na problem podkradania sesji – jeżeli posługujemy się tzw. ciastkiem sesyjnym trzeba wprowadzić dodatkowe mechanizmy weryfikujące ze ciastko nie zostało po prostu przeklejone (w wyniku kradzieży przykladowo).
masz może jakieś artykuły na ten temat do poczytania? Szczególnie związane z mechanizmami weryfikującymi to czy ciastko nie zostało przeklejone.
Wiesz co tak pod reką nic nie mam, ale generalnie z takich rzeczy, o które warto zadbać zeby się zabezpieczyć to jest: kierowanie całego ruchu, który ma cokolwiek związane z sesja (czy to ją tworzy, czy w niej coś umieszcza, czy z niej czyta) po https. Z innych mechanizmów zabezpieczeń można przepisywać wartość ciasteczka sesyjnego (idetyfikator sesji) przy kadym requeście kierowanym do aplikacji, to tez znacząco obniza ryzyko przejęcia sesji. Warto też stosować bardzo dlugie identyfikatory tak aby próba reprodukcji identyfikatora była trudniejsza. Są tez mechanizmy „na sztywno” wiązania sesji z użytkownikiem (poszukaj o session fixtation) lub wiązania sesji z… Czytaj więcej »
Hej co do środowisk rozproszonych stosuje się mechanizm sticky-session. Ale i tak najlepszym zastosowaniem jest JWT. Ale to pewnie wiesz 😉